Log distributed training experiments
9 minute read
During a distributed training experiment, you train a model using multiple machines or clients in parallel. W&B can help you track distributed training experiments. Based on your use case, track distributed training experiments using one of the following approaches:
- Track a single process: Track a rank 0 process (also known as a “leader” or “coordinator”) with W&B. This is a common solution for logging distributed training experiments with the PyTorch Distributed Data Parallel (DDP) Class.
- Track multiple processes: For multiple processes, you can either:
- Track each process separately using one run per process. You can optionally group them together in the W&B App UI.
- Track all processes to a single run.
Track a single process
This section describes how to track values and metrics available to your rank 0 process. Use this approach to track only metrics that are available from a single process. Typical metrics include GPU/CPU utilization, behavior on a shared validation set, gradients and parameters, and loss values on representative data examples.
Within the rank 0 process, initialize a W&B run with wandb.init and log experiments (wandb.log) to that run.
The following sample Python script (log-ddp.py) demonstrates one way to track metrics on two GPUs on a single machine using PyTorch DDP. PyTorch DDP (DistributedDataParallel intorch.nn) is a popular library for distributed training. The basic principles apply to any distributed training setup, but the implementation may differ.
The Python script:
- Starts multiple processes with
torch.distributed.launch. - Checks the rank with the
--local_rankcommand line argument. - If the rank is set to 0, sets up
wandblogging conditionally in thetrain()function.
if __name__ == "__main__":
# Get args
args = parse_args()
if args.local_rank == 0: # only on main process
# Initialize wandb run
run = wandb.init(
entity=args.entity,
project=args.project,
)
# Train model with DDP
train(args, run)
else:
train(args)
Explore an example dashboard showing metrics tracked from a single process.
The dashboard displays system metrics for both GPUs, such as temperature and utilization.
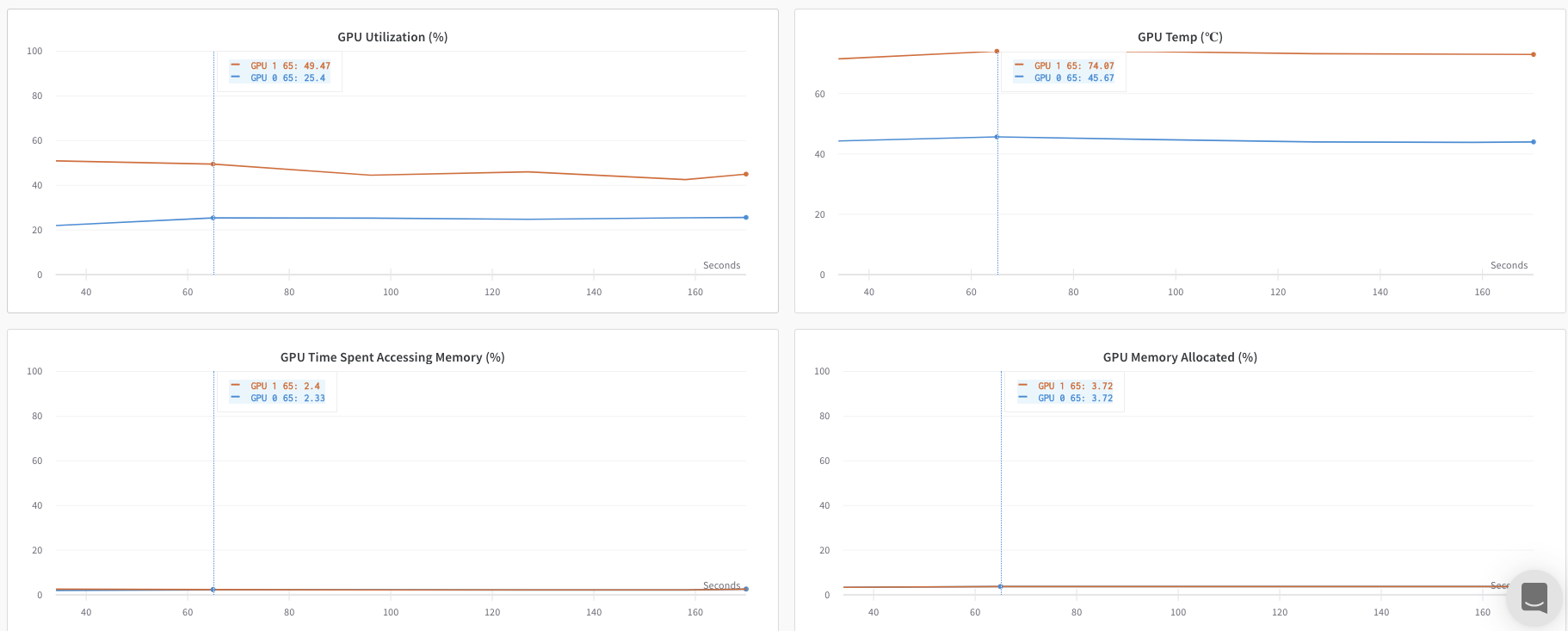
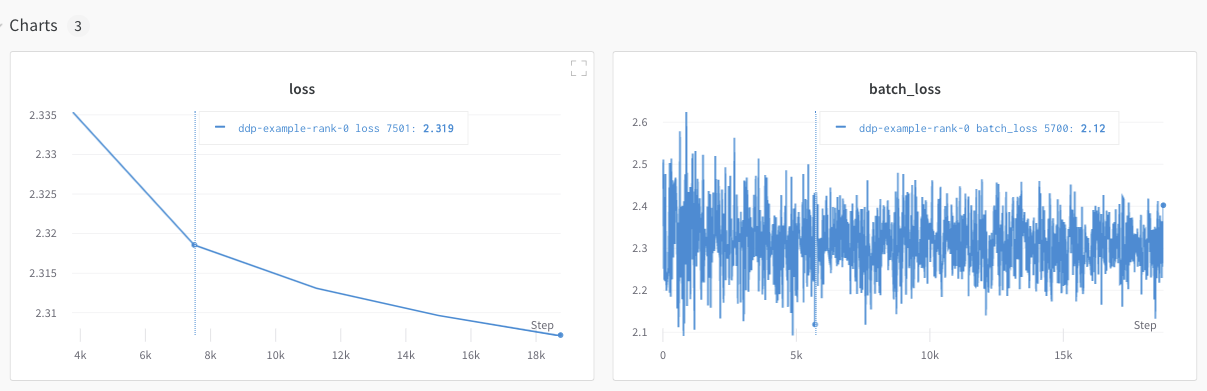
However, the loss values as a function epoch and batch size were only logged from a single GPU.
Track multiple processes
Track multiple processes with W&B with one of the following approaches:
- Tracking each process separately by creating a run for each process.
- Tracking all processes to a single run.
Track each process separately
This section describes how to track each process separately by creating a run for each process. Within each run you log metrics, artifacts, and forth to their respective run. Call wandb.finish() at the end of training, to mark that the run has completed so that all processes exit properly.
You might find it difficult to keep track of runs across multiple experiments. To mitigate this, provide a value to the group parameter when you initialize W&B (wandb.init(group='group-name')) to keep track of which run belongs to a given experiment. For more information about how to keep track of training and evaluation W&B Runs in experiments, see Group Runs.
The following Python code snippet demonstrates how to set the group parameter when you initialize W&B:
if __name__ == "__main__":
# Get args
args = parse_args()
# Initialize run
run = wandb.init(
entity=args.entity,
project=args.project,
group="DDP", # all runs for the experiment in one group
)
# Train model with DDP
train(args, run)
Explore the W&B App UI to view an example dashboard of metrics tracked from multiple processes. Note that there are two W&B Runs grouped together in the left sidebar. Click on a group to view the dedicated group page for the experiment. The dedicated group page displays metrics from each process separately.
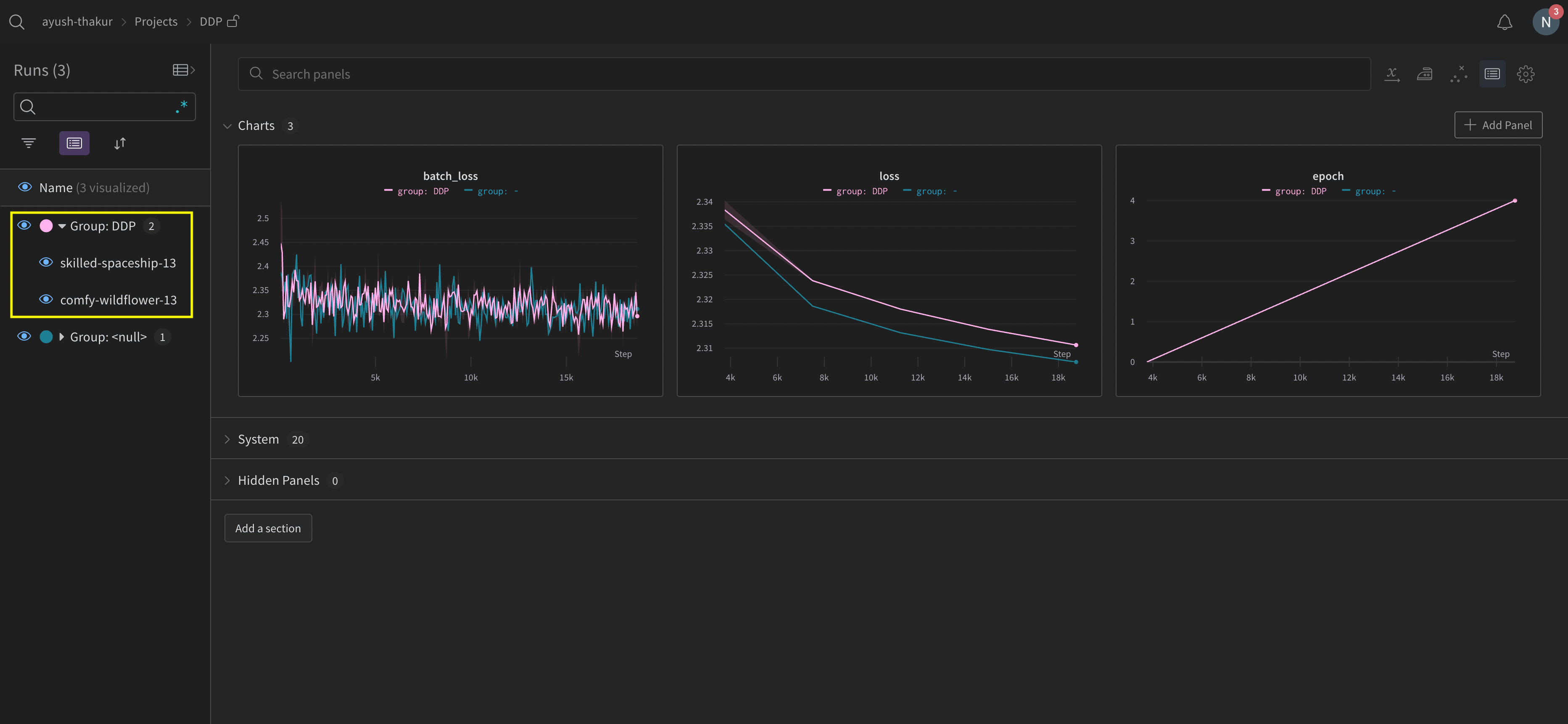
The preceding image demonstrates the W&B App UI dashboard. On the sidebar we see two experiments. One labeled ’null’ and a second (bound by a yellow box) called ‘DPP’. If you expand the group (select the Group dropdown) you will see the W&B Runs that are associated to that experiment.
Track all processes to a single run
x_ (such as x_label) are in public preview. Create a GitHub issue at https://github.com/wandb/wandb to provide feedback.v0.19.9 or newer.In this approach you use a primary node and one or more worker nodes. Within the primary node you initialize a W&B run. For each worker node, initialize a run using the run ID used by the primary node. During training each worker node logs to the same run ID as the primary node. W&B aggregates metrics from all nodes and displays them in the W&B App UI.
Within the primary node, initialize a W&B run with wandb.init. Pass in a wandb.Settings object to the settings parameter (wandb.init(settings=wandb.Settings()) wit with the following:
- The
modeparameter set to"shared"to enable shared mode. - A unique label for
x_label. You use the value you specify forx_labelto identify which node the data is coming from in logs and system metrics in the W&B App UI. If left unspecified, W&B creates a label for you using the hostname and a random hash. - Set the
x_primaryparameter toTrueto indicate that this is the primary node.
Make note of the run ID of the primary node. Each worker node needs the run ID of the primary node.
x_primary=True distinguishes a primary node from worker nodes. Primary nodes are the only nodes that upload files shared across nodes such as configuration files, telemetry and more. Worker nodes do not upload these files.For each worker node, initialize a W&B run with wandb.init and provide the following:
- A
wandb.Settingsobject to thesettingsparameter (wandb.init(settings=wandb.Settings()) with:- The
modeparameter set to"shared"to enable shared mode. - A unique label for
x_label. You use the value you specify forx_labelto identify which node the data is coming from in logs and system metrics in the W&B App UI. If left unspecified, W&B creates a label for you using the hostname and a random hash. - Set the
x_primaryparameter toFalseto indicate that this is a worker node.
- The
- Pass the run ID used by the primary node to the
idparameter. - Optionally set
x_update_finish_statetoFalse. This prevents non-primary nodes from updating the run’s state tofinishedprematurely, ensuring the run state remains consistent and managed by the primary node.
The following sample code demonstrates the high level requirements for tracking multiple processes to a single run:
import wandb
# Initialize a run in the primary node
run = wandb.init(
entity="entity",
project="project",
settings=wandb.Settings(x_label="rank_0", mode="shared", x_primary=True)
)
# Note the run ID of the primary node.
# Each worker node needs this run ID.
run_id = run.id
# Initialize a run in a worker node using the run ID of the primary node
run = wandb.init(
settings=wandb.Settings(x_label="rank_1", mode="shared", x_primary=False),
id=run_id,
)
# Initialize a run in a worker node using the run ID of the primary node
run = wandb.init(
settings=wandb.Settings(x_label="rank_2", mode="shared", x_primary=False),
id=run_id,
)
In a real world example, each worker node might be on a separate machine.
View console logs from multi node processes in the project that the run logs to:
- Navigate to the project that contains the run.
- Click on the Runs tab in the left sidebar.
- Click on the run you want to view.
- Click on the Logs tab in the left sidebar.
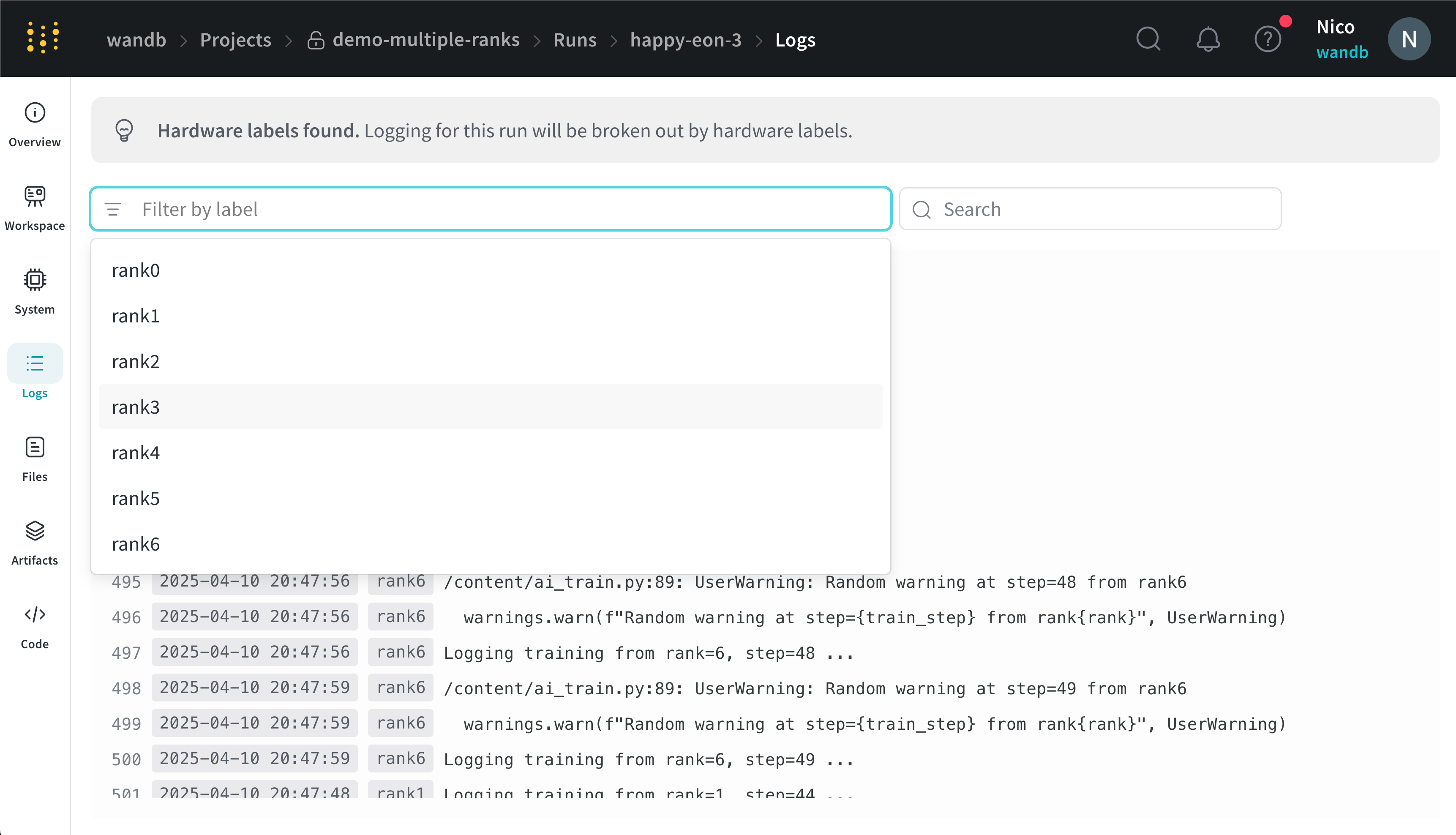
You can filter console logs based on the labels you provide for x_label in the UI search bar located at the top of the console log page. For example, the following image shows which options are available to filter the console log by if values rank0, rank1, rank2, rank3, rank4, rank5, and rank6 are provided to x_label.`
W&B aggregates system metrics from all nodes and displays them in the W&B App UI. For example, the following image shows a sample dashboard with system metrics from multiple nodes. Each node possesses a unique label (rank_0, rank_1, rank_2) that you specify in the x_label parameter.
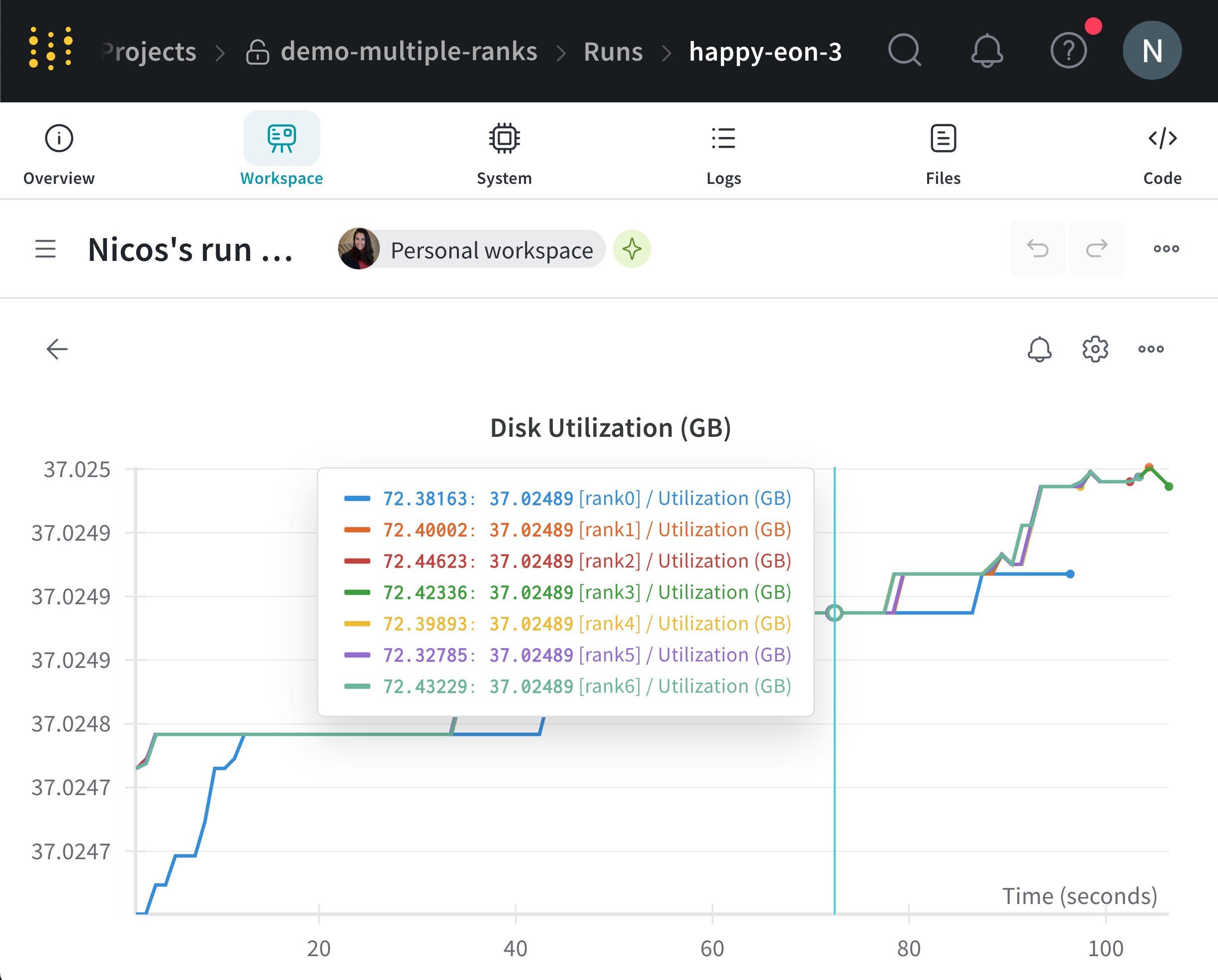
See Line plots for information on how to customize line plot panels.
Example use cases
The following code snippets demonstrate common scenarios for advanced distributed use cases.
Spawn process
Use the wandb.setup()method in your main function if you initiate a run in a spawned process:
import multiprocessing as mp
def do_work(n):
run = wandb.init(config=dict(n=n))
run.log(dict(this=n * n))
def main():
wandb.setup()
pool = mp.Pool(processes=4)
pool.map(do_work, range(4))
if __name__ == "__main__":
main()
Share a run
Pass a run object as an argument to share runs between processes:
def do_work(run):
run.log(dict(this=1))
def main():
run = wandb.init()
p = mp.Process(target=do_work, kwargs=dict(run=run))
p.start()
p.join()
if __name__ == "__main__":
main()
W&B can not guarantee the logging order. Synchronization should be done by the author of the script.
Troubleshooting
There are two common issues you might encounter when using W&B and distributed training:
- Hanging at the beginning of training - A
wandbprocess can hang if thewandbmultiprocessing interferes with the multiprocessing from distributed training. - Hanging at the end of training - A training job might hang if the
wandbprocess does not know when it needs to exit. Call thewandb.finish()API at the end of your Python script to tell W&B that the Run finished. The wandb.finish() API will finish uploading data and will cause W&B to exit.
We recommend using the wandb service to improve the reliability of your distributed jobs. Both of the preceding training issues are commonly found in versions of the W&B SDK where wandb service is unavailable.
Enable W&B Service
Depending on your version of the W&B SDK, you might already have W&B Service enabled by default.
W&B SDK 0.13.0 and above
W&B Service is enabled by default for versions of the W&B SDK 0.13.0 and above.
W&B SDK 0.12.5 and above
Modify your Python script to enable W&B Service for W&B SDK version 0.12.5 and above. Use the wandb.require method and pass the string "service" within your main function:
if __name__ == "__main__":
main()
def main():
wandb.require("service")
# rest-of-your-script-goes-here
For optimal experience we do recommend you upgrade to the latest version.
W&B SDK 0.12.4 and below
Set the WANDB_START_METHOD environment variable to "thread" to use multithreading instead if you use a W&B SDK version 0.12.4 and below.
Feedback
Was this page helpful?
Glad to hear it! If you have further feedback, please let us know.
Sorry to hear that. Please tell us how we can improve.